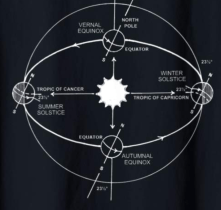
I was writing some code to perform some celestial calculations. A lot of it handled changes in positions from certain rotations (orbits, revolutions). There are also instances where time is treated as a rotation (ex: 1 hour of rotation is 15 degrees). The best notation for the rotation depends on what is being done. Here are the rotation notations that might be used.
- Radians
- Degrees
- Decimal Degrees
- Degrees, Minutes, Seconds
- Hours
- Decimal Hours
- Hours, Minutes, Seconds
Conversion from one to another is easy. What I did find challenging is ensuring that the right conversion had been performed before working with it. The trig functions expect to always receive radians. More than once I made the mistake of converting to the wrong unit before performing a calculation. Rather then continue forward on a path that has many opportunities for mistakes I made a single class to represent rotations that can be used in various scenarios. It will always internally represent rotations in degrees. If I want to explicitly convert the class to a specific type there are methods to explicitly convert to any of the other rotation types.
Instances of this custom type also can be assigned a preferred notation. This preferred notation is used when printing it to the output stream. This allows a preferred format to be assigned without risking making any conversion mistakes.
The interface for the class and the support class follows.
#include <stdio.h>
#include <cmath>
#include <iostream>
typedef double Degree;
typedef double Hour;
typedef double Minute;
typedef double Second;
typedef double Radian;
enum RotationNotation {
NOTATION_DEGREES,
NOTATION_DMS,
NOTATION_HOURS,
NOTATION_HMS,
NOTATION_RADIANS
};
class Rotation;
struct HMS {
Hour H;
Minute M;
Second S;
};
struct DMS {
Degree D;
Minute M;
Second S;
} ;
std::ostream& operator << (std::ostream& o, const HMS& h);
std::ostream& operator << (std::ostream& o, const DMS& d);
std::ostream& operator << (std::ostream& o, const Rotation a);
double sin(const Rotation& source);
double cos(const Rotation& source);
Hour RadToHour(const Radian );
Hour HMSToHour(const HMS& hms);
Hour DMSToHour(const DMS&);
Hour DegToHour(const Degree degrees);
DMS RadToDMS(const Radian);
DMS DegToDMS(const Degree degrees);
DMS HourToDMS(const Hour hour);
DMS HMSToDMS(const HMS&);
HMS RadToHMS(const Radian);
HMS DegToHMS(const Degree degrees);
HMS DMSToHMS(const DMS&);
HMS HourToHMS(const Hour);
Degree RadToDeg(const Radian);
Degree DMSToDeg(const DMS& );
Degree HMSToDeg(const HMS&);
Degree HourToDeg(const Hour hour);
Radian HourToRad(const Hour);
Radian HMSToRad(const HMS& );
Radian DMSToRad(const DMS& );
Radian DegToRad(const Degree);
class Rotation {
private:
Degree _degrees;
RotationNotation _notation;
public:
Rotation();
Rotation(const Rotation& source);
RotationNotation getNotation() const;
void setNotation(RotationNotation);
const Degree getDegrees() const;
const Hour getHours() const ;
const Minute getRadians() const ;
const DMS getDMS() const ;
const HMS getHMS() const ;
void setDegrees(const Degree degree) ;
void setHours(const Hour hour) ;
void setRadians(const Radian rad) ;
void setDMS(const DMS& dms) ;
void setHMS(const HMS& hms) ;
};
Download Code 2.0 KB
-30-